Cloud Dataflow & Cloud Dataproc 관련 내용을 정리합니다.
Which GCP service to use
| Which GCP service to use ❓ - Situation | GCP service |
|---|---|
| You have lots of files that need processing you may already be familiar with the Hadoop/Spark ecoystem | Dataproc |
| Anomaly detection model in real-time with pub/sub | Dataflow |
| Fully-managed, no-ops, GREAT for batch and streaming, built on beam | Dataflow |
| Provides clear separation between processing. Portability is big benefit. | Dataflow |
Typical big data pipeline for streaming Pub/Sub → _____ → BQ |
Dataflow |
| Integrate open source software like Apache Spark, NVIDIA RAPIDS, and Jupyter notebooks with Google Cloud AI services and GPUs to help accelerate your machine learning and AI development. | Create your ideal data science environment by spinning up a purpose-built Dataproc cluster. |
Move your Hadoop and Spark clusters to the cloud - Enterprises are migrating their existing on-premises Apache Hadoop and Spark clusters over to ______ to manage costs and unlock the power of elastic scale. |
With Dataproc, enterprises get a fully managed, purpose-built cluster that can autoscale to support any data or analytics processing job. |
Cloud Dataflow
Dataflow can be used for both real-time/Stream predictions and batch inferences.
Dataflow
a fully managed service for strongly consistent, parallel data-processing pipelines.
- Unified batch & stream service which is their managed Apache beam
- Running on Apache Beam pipelines
- Serverless approach : GCP takes care of provisioning & managing the compute.
- Simplify operations and fully managed
- Autoscaling of resources and dynamic work rebalancing
⇒ Remove operational overhead from data engineering workloads
- Without worrying about the compute.
- Parallelized
- Reliable where on-demand resources are created : Streaming data analytics with speed
- Support languages :
Java, Python, Go
- ❌ All the code in DataFlow needs to be translated to Java before use.
- Apache Beam (DataFlow SDK) supports execution in Python, Java and Go.
Cloud Dataproc
Dataproc
a fast, easy to use, managed Spark and Hadoop (clusters/jobs) service for distributed data processing.
- fully managed and highly scalable service for running Apache Spark, Apache Flink, Presto, and 30+ open source tools and frameworks.
- Provide management, integration, development tools for unlocking the power of rich open source data processing tools.
- Not fully managed service : have to configure the cluster & one can shut down the costs when service is not in use.
⇒ when you need Spark/Hadoop clusters sized for your workloads precisely.- Benefits of dataproc over on prem
- Making sure they're efficiently utilized and tooler for various workloads, e.g. being under or overprovisioned
- Dataproc can spin up as many or as few cluster resources as needed. Can automate when cluster shutdown based on how long cluster idle, or at timestamp, or seconds, or after job done.
- Can use pre-empts to save money
- Can lift and shift existing hadoop workloads
USE-CASES
- Cloud Dataflow
- How to build a fraud detection solution
- Anomaly detection reference architecture using Pub/sub → Dataflow → AI Platform → BigQuery

- Anomaly detection reference architecture using Pub/sub → Dataflow → AI Platform → BigQuery
- How to build a fraud detection solution
Decision Tree for Data processing : Cloud Dataproc $vs.$ Cloud Dataflow
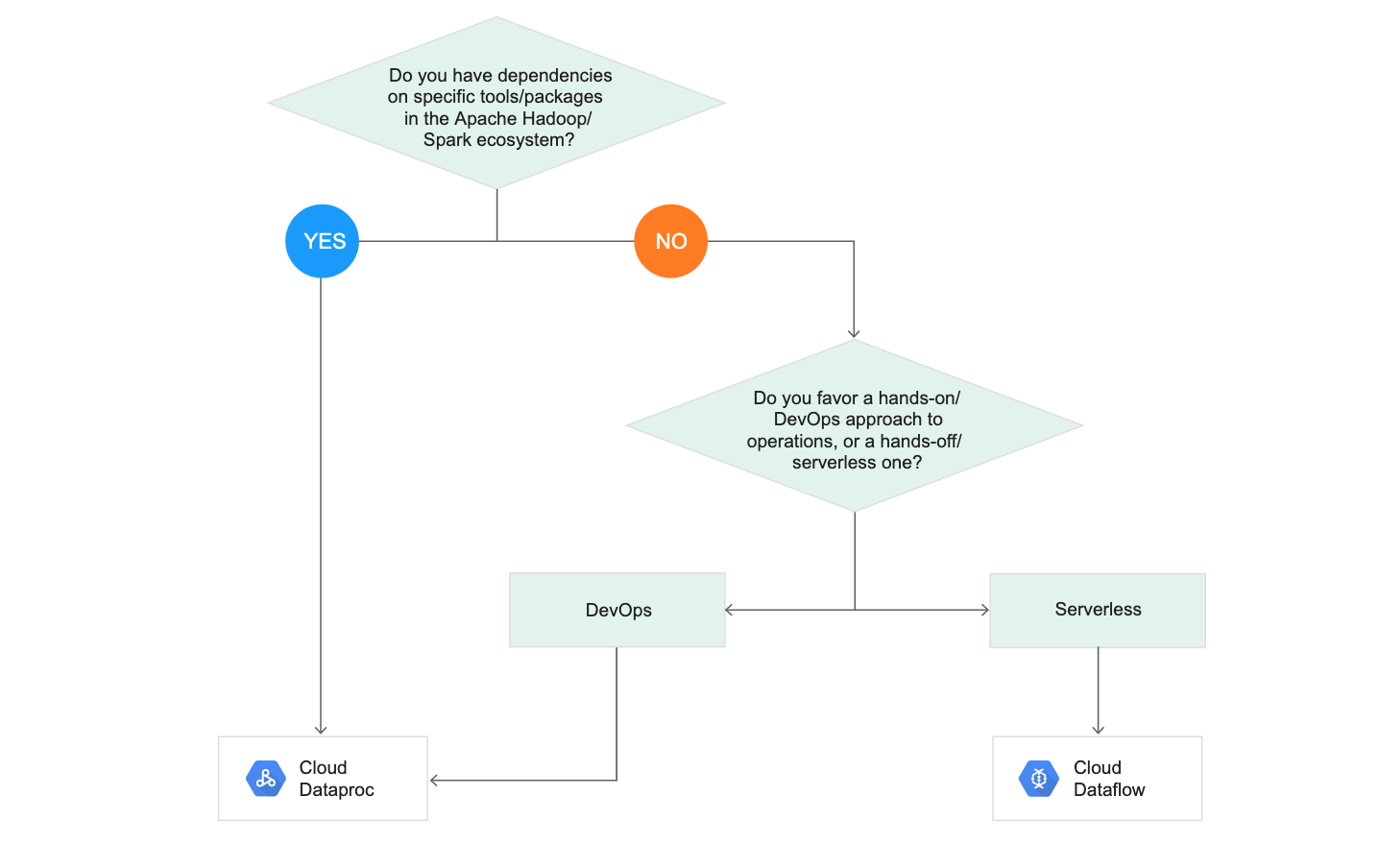
Q1.
You are building an ML model to detect anomalies in real-time sensor data. You will use Pub/Sub to handle incoming requests. You want to store the results for analytics and visualization. How should you configure the pipeline?
- ⭕ A. 1 = Dataflow, 2 = AI Platform, 3 = BigQuery
- B. 1 = DataProc, 2 = AutoML, 3 = Cloud Bigtable
- C. 1 = BigQuery, 2 = AutoML, 3 = Cloud Functions
- D. 1 = BigQuery, 2 = AI Platform, 3 = Cloud Storage
Q 29.
You have trained a model on a dataset that required computationally expensive preprocessing operations. You need to execute the same preprocessing at prediction time. You deployed the model on AI Platform for high-throughput online prediction*. Which architecture should you use?
- A. Validate the accuracy of the model that you trained on preprocessed data.
Create a new model that uses the raw data and is available in real time.Deploy the new model onto AI Platform for online prediction. - ⭕ B. Send incoming prediction requests to a Pub/Sub topic. Transform the incoming data using a Dataflow job. Submit a prediction request to AI Platform using the transformed data. Write the predictions to an outbound Pub/Sub queue.
- C. Stream incoming prediction request data into
Cloud Spanner. Create a view to abstract your preprocessing logic. Query the view every second for new records. Submit a prediction request to AI Platform using the transformed data. Write the predictions to an outbound Pub/Sub queue. - D. Send incoming prediction requests to a Pub/Sub topic. Set up a Cloud Function that is triggered when messages are published to the Pub/Sub topic. Implement your preprocessing logic in the
Cloud Function. Submit a prediction request to AI Platform using the transformed data. Write the predictions to an outbound Pub/Sub queue.
Source&Reference : Dataflow | Google Cloud, GCP Flowcharts · Missives about mostly GCP related things