[EXAMTOPIC] Section 2-2 Architecting ML solutions : Choosing appropriate Google Cloud hardware components 관련 내용을 정리합니다.

Hardware types
- How CPU, GPU, TPU works
- When to use CPU, GPU, TPU
- edge devices
Quick Comparisons CPU/GPU/TPU
| CPU central processing unit | GPU graphics processing unit | TPU tensor processing unit |
|---|---|---|
| CPU controls instructions and data flow to and from parts of the computer, relying on a chipset -a group of microchips located on the motherboard | GPU is a computer chip developed by NVIDIA that performs rapid mathematical calculations, primarily for rendering images. | A TPU is an AI accelerator application-specific integrated circuit (ASIC) developed by Google for neural network machine learning algorithms and, in particular, to work with TensorFlow. |
Good fit with CPU |
Good fit with GPU |
Good fit with TPU |
|---|---|---|
| Quick prototyping - Simple and quickly trained models | Medium-to-large models with larger effective batch sizes | Large and very large models with very large effective batch sizes |
| Models with small effective batch sizes | Models used for image processing | Models that train for a long period of time |
| Models that are limited by available 10 or the networking bandwidth of the host system | Models for which source does not exist or is too onerous to change | Models dominated by matrix computations |
How a CPU works
CPU : 범용프로세서general purpose processor based on the von Neumann architecture
- works with software and memory 소프트웨어/메모리와 함께 작동
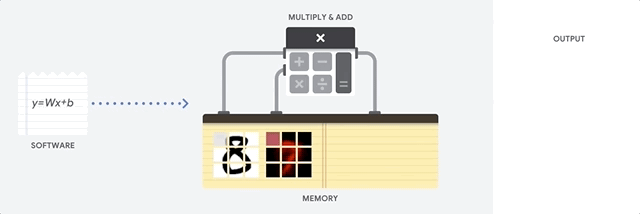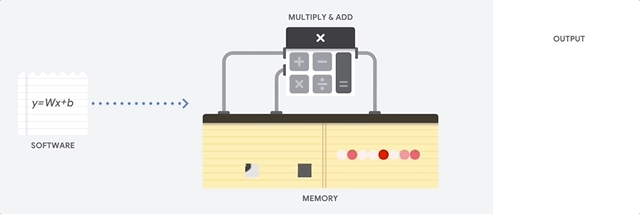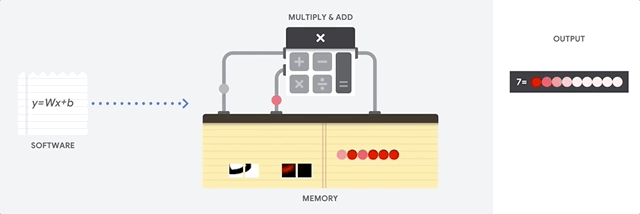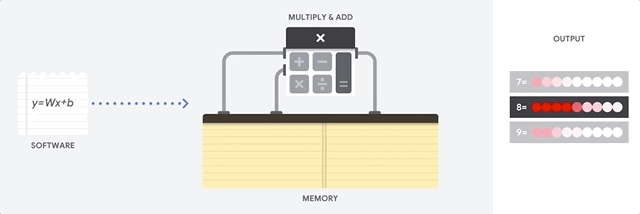
Benefit of CPU : flexibility
Von Neumann architecture > you can load any kind of software for millions of different applications. (CPU for word processing in a PC, controlling rocket engines, executing bank transactions, or classifying images with a neural network.)Limitations of CPU
- CPU is so flexible ⇒ the hardware doesn't always know what would be next calculation until it reads the next instruction from the software. 하드웨어가 소프트웨어에서 다음 명령을 읽기 전까지는 다음 연산에 대해서 알지 못한다.
- von Neumann bottleneck 폰 노이만 병목현상
- CPU has to store the calculation results on memory inside CPU (so called registers or L1 cache) for every single calculation
- CPU의 Arithmetic Logic Unit을 하나씩 실행하고, 모든 연산의 결과를 매번 내부 메모리에 접근해 저장하는 방식 (ALU: multipliers and adders를 보유/제어하는 구성 요소 ) ⇒ limiting the total throughput and consuming significant energy
How a GPU works
GPU : with 2,500–5,000 ALUs in a single processor, higher throughput than a CPU
execute thousands of multiplications and additions simultaneously. 수천 개의 곱/덧셈 동시에 실행할 수 있다.
GPU architecture
- works well on applications with massive parallelism ; matrix multiplication in NN ( the reason why GPU is the most popular processor in DL )
still a general purpose processor that has to support millions of different applications and software. 수백만개의 서로 다른 응용 프로그램, 소프트웨어를 지원해야하는 범용 프로세서
von Neumann bottleneck 폰 노이만 병목현상 : GPU ALU의 수천 개의 단일 계산에 대해서 중간 계산 결과를 읽고 저장하기 위해 _registers/shared memory에 액세스_한다.
- GPU performs more parallel calculations on its thousands of ALUs ⇒ spends proportionally more energy accessing memory and also increases footprint of GPU for complex wiring 수천개의 ALU로 병렬 계산을 수행하기 때문에 메모리 엑세스에 비례해 더 많은 에너지를 소비하고, GPU 공간이 증가한다.
How a TPU works
TPU is domain specific architecture for deep learning : Achieve higher efficiency by tailoring architecture to characteristics of domain. 도메인별 아키텍쳐 를 구축
general purpose processor 범용 프로세서를 설계하지 않고 신경망 모델 연산 부하에 특화된 matrix processor매트릭 프로세서로 설계한 것이다. (이는 TPU로 run word processors, control rocket engines, execute bank transactions 와 같은 작업을 할 수는 없지만, 신경망 모델의 대규모 곱셈/덧셈 연산 작업을 할 수 있다는 의미)
Computation at blazingly fast speeds, Consuming much less power, Smaller physical footprint
Reduction of the von Neumann bottleneck ⇒ Systolic array architecture
- 매트릭스 처리가 주요 작업이기 때문에 TPU의 하드웨어 설계자가 연산 단계를 알고 수천개의 multipliers, adders를 배치하고, 서로 직접 연결해 a large physical matrix of operations 큰 물리적 연산 행렬을 형성한다.

- 매트릭스 처리가 주요 작업이기 때문에 TPU의 하드웨어 설계자가 연산 단계를 알고 수천개의 multipliers, adders를 배치하고, 서로 직접 연결해 a large physical matrix of operations 큰 물리적 연산 행렬을 형성한다.
Cloud TPU v2 : 2 systolic arrays of 128 x 128 , aggregating 32,768 ALUs ALUs for 16 bit floating point values in a single processor.
Systolic Array 시스톨릭 배열 : During the whole process of massive calculations and data passing, No memory access is required at all.
| How a systolic array executes the neural network calculations |
|---|
 |
| 1. TPU loads the parameters from memory into the matrix of multipliers and adders. |
| 2. TPU loads data from memory. |
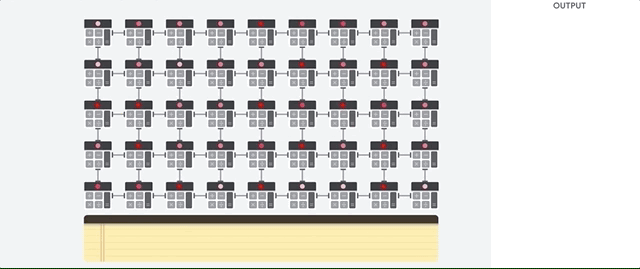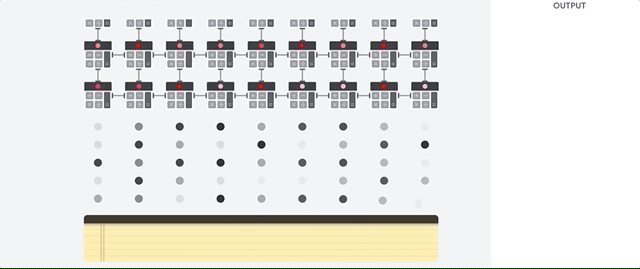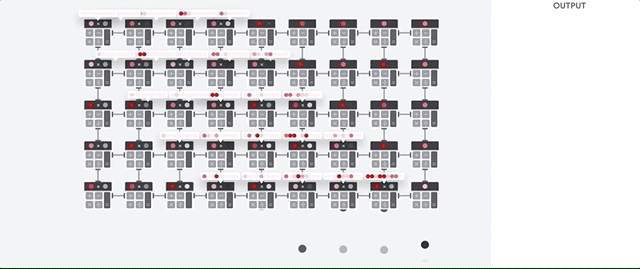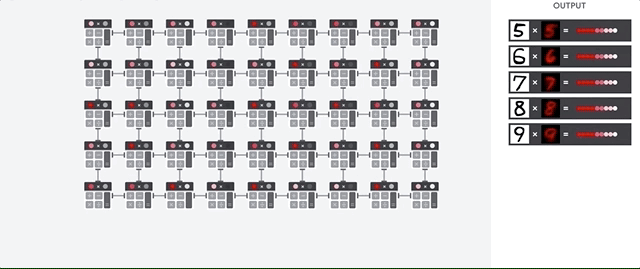 |
| 3. As each multiplication is executed, the result will be passed to next multipliers while taking summation at the same time. So the output will be the summation of all multiplication result between data and parameters. |
WHEN TO USE CPU, GPU, TPU
CPUs
- Quick prototyping that requires maximum flexibility 신속한 프로토타입 생성
- Simple models that do not take long to train 학습 시간 짧은 단순 모델
- Small models with small, effective batch sizes 유효 배치 사이즈가 작은 소형 모델
- Models that are dominated by custom TensorFlow/PyTorch/JAX operations written in C++ C++로 작성된 커스텀 TensorFlow/PyTorch/JAX 작업으로 대부분 구성된 모델
- Models that are limited by available I/O or the networking bandwidth of the host system 호스트 시스템의 사용 가능한 I/O, 네트워크 대역폭 제한이 존재하는 모델
GPUs
- Models with a significant number of custom TensorFlow/PyTorch/JAX operations that must run at least partially on CPUs
최소한 부분적으로라도 CPU에서 실행해야하는 커스텀 작업이 있는 경우- Models with TensorFlow/PyTorch ops that are not available on Cloud TPU
- Medium-to-large models with larger effective batch sizes
TPUs
- Models dominated by matrix computations
- Models with no custom TensorFlow/PyTorch/JAX operations* inside the main training loop
- Models that train for weeks or months 학습 시간 몇 주 혹은 몇 달
- Large models with large effective batch sizes
Cloud TPUs are not suited
- Linear algebra programs that require frequent branching or are dominated by element-wise algebra
- Workloads that access memory in a sparse manner
- Workloads that require high-precision arithmetic
- Neural network workloads that contain custom operations in the main training loop
Source&Reference : Cloud TPU 소개 | Google Cloud| Cloud TPU | Google Cloud | What makes TPUs fine-tuned for deep learning? | Google Cloud Blog
'Certificate - DS > Machine learning engineer' 카테고리의 다른 글
| Deep Learning VM Image (0) | 2021.11.27 |
|---|---|
| Production ML Systems - Design Training&Serving Architecture (0) | 2021.11.26 |
| Professional Machine Learning Engineer 샘플 문제 정리 (0) | 2021.11.26 |
| Cloud IAM, API Gateway - Security, Privacy, compliance, legal issues (0) | 2021.11.26 |
| Explainable AI, Feature Attribution (2) | 2021.11.26 |