Q 9.
You are developing ML models with AI Platform for image segmentation on CT scans. You frequently update your model architectures based on the newest available research papers, and have to rerun training on the same dataset to benchmark their performance. You want to minimize computation costs and manual intervention while having version control for your code. What should you do?
CI/CD for Kubeflow pipelines
- ❌ A. Use
Cloud Functionsto identify changes to your code inCloud Storageand trigger a retraining job.- ❌ B. Use the gcloud command-line tool to submit training jobs on AI Platform when you update your code.
- ⭕ C. Use
Cloud Buildlinked with Cloud Source Repositories to trigger retraining when new code is pushed to the repository.- ❌ D. Create an automated workflow in
Cloud Composerthat runs daily and looks for changes in code inCloud Storageusing a sensor.
Q 10.
Your team needs to build a model that predicts whether images contain a driver's license, passport, or credit card. The data engineering team already built the pipeline and generated a dataset composed of 10,000 images with driver's licenses, 1,000 images with passports, and 1,000 images with credit cards. You now have to train a model with the following label map: ['drivers_license', 'passport', 'credit_card']. Which loss function should you use?
Proper metric for multi-class (3) classification
- ❌ A. Categorical hinge
- ❌ B. Binary cross-entropy
- ⭕ C. Categorical cross-entropy
- ❌ D. Sparse categorical cross-entropy
Categorical Entropy & Sparse Categorical Entropy
Categorical entropy is better to use when you want to prevent the model from giving more importance to a certain class. Or if the classes are very unbalanced you will get a better result by using Categorical entropy.
Sparse Categorical Entropy is a more optimal coice if you have a huge amount of classes, enough to make a lot of memory usage, so since sparse categorical entropy uses less columns it uses less memory.
Q 11.
You are designing an ML recommendation model for shoppers on your company's ecommerce website. You will use Recommendations AI to build, test, and deploy your system. How should you develop recommendations that increase revenue while following best practices?
Objective based on the Recommendation types
- ❌ A. Use the Other Products You May Like recommendation type to increase the click-through rate.
- ⭕ B. Use the Frequently Bought Together recommendation type to increase the shopping cart size for each order.
- ❌ C.
Import your user eventsand then your product catalog to make sure you have the highest quality event stream. - ❌ D. Because it will take time to collect and record product data,
use placeholder values for the product catalog to test the viability of the model.
Q 12.
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
Which endpoints should the Enrichment Cloud Functions call?
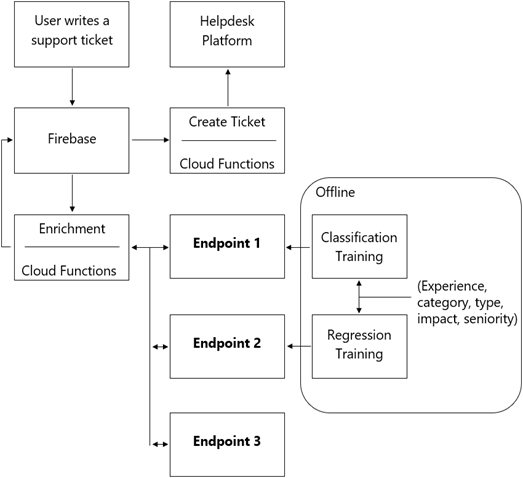
Architecture of Serverless ML model & Cloud ML API $vs.$ AutoML
- ❌ A. 1 = AI Platform, 2 = AI Platform, 3 = AutoML Vision
- ❌ B. 1 = AI Platform, 2 = AI Platform,
3 = AutoML Natural Language
→ Tickets are not expected to have any domain-specific terms or jargon : NOT INCLUDE SPECIFIC TERMS MEANING THAT YOU DONT NEED CUSTOM ML MODEL.- ⭕ C. 1 = AI Platform, 2 = AI Platform, 3 = Cloud Natural Language API
→ SENTIMENT ANALYSIS PROVIDED BYCloud Natural Language API- ❌ D. 1 = Cloud Natural Language API, 2 = AI Platform, 3 = Cloud Vision API
Firebase, Cloud Functions, AI Platform, Cloud ML API for real time & serverless ML model system
| No | Architecture of a Serverless Machine Learning Model |
|---|---|
| workflow | Architecture of a Serverless Machine Learning Model to enrich support tickets with metadata before they reach a support agent |
| 1 | A user writes a ticket to Firebase, which triggers a Cloud Function. |
| 2 | The Cloud Function calls 3 different endpoints to enrich the ticket |
| 2-1 | → (1) An AI Platform endpoint, where the function can predict the priority. |
| 2-2 | → (2) An AI Platform endpoint, where the function can predict the resolution time. |
| 2-3 | → (3) The Natural Language API to do sentiment analysis and word salience. |
| 3 | For each reply, the Cloud Function updates the Firebase real-time database. |
| 4 | The Cloud Function then creates a ticket into the helpdesk platform using the RESTful API. |
-
- Real-time database that a client can update, and it displays real-time updates to other subscribed clients
- Firebase can use
Cloud Functionsto call an external API, such as one that your helpdesk platform makes available. (Workflow에e표시) - Firebase works on desktop and mobile platforms and can be developed in various languages. When Firebase experiences unreliable internet connections, it can cache data locally.
Sentiment analysis and autotagging : Cloud Natural Language API for Sentiment analysis, Entity analysis with salience calculation, Syntax analysis easily accessible from
Cloud Functionsas a RESTful API.- Sentiment analysis on the ticket description helps agents know how the customer feels.
- Wild autotagging : By using a tool that identifies the most important words in the description, the agent can narrow down the subject matter. (⇒ Entity Analysis)
'Certificate - DS > Machine learning engineer' 카테고리의 다른 글
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q17-Q20 (0) | 2021.12.10 |
|---|---|
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q13-Q16 (0) | 2021.12.10 |
| [EXAMTOPIC] Data Prep - Imbalanced data (0) | 2021.12.09 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q5-Q8 (0) | 2021.12.09 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q1-Q4 (0) | 2021.12.09 |