Q1.
You are building an ML model to detect anomalies in real-time sensor data. You will use Pub/Sub to handle incoming requests. You want to store the results for analytics and visualization. How should you configure the pipeline?
Pipeline for Anomaly detection model in Real-time with pub/sub
- ⭕ A. 1 = Dataflow, 2 = AI Platform, 3 = BigQuery
→Dataflowis MUST for real-time/streaming data- B. 1 = DataProc, 2 = AutoML, 3 = Cloud Bigtable
- C. 1 = BigQuery, 2 = AutoML, 3 = Cloud Functions
- D. 1 = BigQuery, 2 = AI Platform, 3 = Cloud Storage
Dataflow + AIplatform
| Pub/sub → Dataflow → AI Platform → BigQuery |
|---|
Detecting anomalies in financial transactions by using AI Platform, Dataflow, and BigQuery |
Dataflow : Write transaction data from the sample dataset to a transactions table in BigQuery. |
| → → Send microbatched requests to the hosted model to retrieve fraud probability predictions. |
→ → write the results to a fraud_detection table in BigQuery. |
AI Platform : Deploy the model for online prediction. |
BigQuery : Run a query that joins these tables to see the probability of fraud for each transaction. |
Dataflow + BigQueryML
| Pub/sub → Dataflow → BigQueryML |
|---|
Building a secure anomaly detection solution using Dataflow, BigQuery ML, and Cloud Data Loss Prevention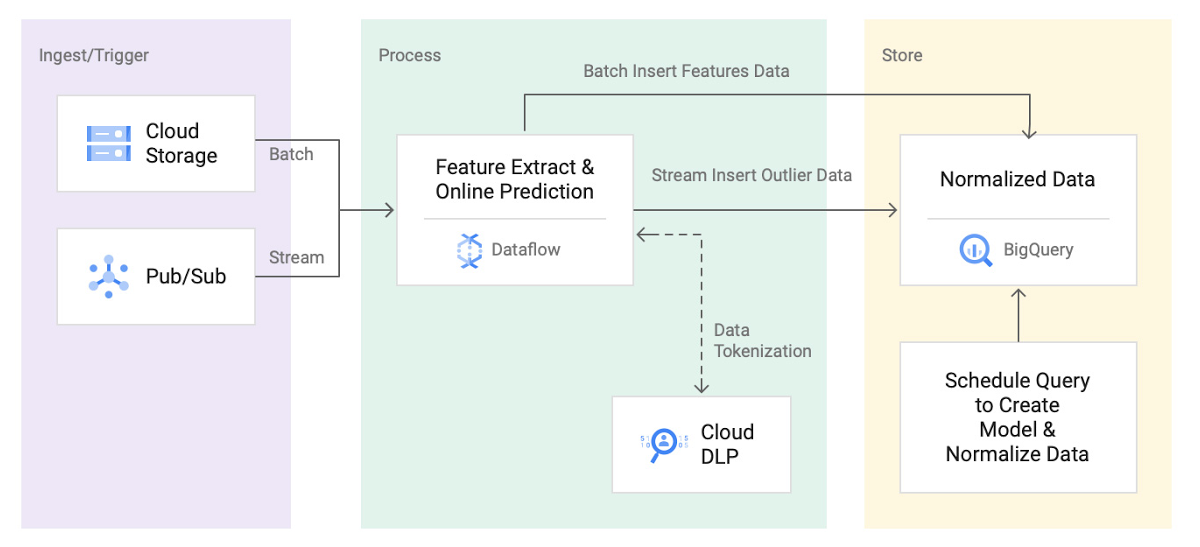 |
 |
Dataflow and Pub/Sub : Generating synthetic data to simulate production volume |
Dataflow : Extracting features & real-time(Online) prediction |
BigQuery ML : Train and normalize data using built-in k-means clustering model. |
| → → ✔ Storing data in a partitioned table to quickly select training data using filters for days (e.g. 10 days) and a group of subscribers (e.g. users from organization X). |
| → → Train models by using standard SQL & automate overall model creation and training processes : (stored procedures and scheduled queries |
| → → Create a k-means clustering model in less than 15 minutes for a terabyte-scale dataset. (After experimenting with multiple cluster sizes, our model evaluation suggested that we used four). |
| → → Normalized the data by finding a normalized distance for each cluster. |
Dataflow and Cloud DLP : De-identifying sensitive data. |
- ✔ To handle large volumes of daily data (20 TB) : ingestion-time partitioned tables & clustering by the 'subscriberID' and dstSubnet field.
Q2.
Your organization wants to make its internal shuttle service route more efficient. The shuttles currently stop at all pick-up points across the city every 30 minutes between 7 am and 10 am. The development team has already built an application on
Google Kubernetes Enginethat requires users to confirm their presence and shuttle station one day in advance. What approach should you take?
OPTIMAL APPROACH TO MAKE SERVICE "ROUTE" MORE EFFICIENT with a application on GKE contains information that users' presence & shuttle station in advance.
- ❌ A. 1. Build a tree-based regression model that predicts how many passengers will be picked up at each shuttle station. 2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the prediction.
- ❌ B. 1. Build a tree-based classification model that predicts whether the shuttle should pick up passengers at each shuttle station. 2. Dispatch an available shuttle and provide the map with the required stops based on the prediction.
- ⭕ C. 1. Define the optimal route as the shortest route that passes by all shuttle stations with confirmed attendance at the given time under capacity constraints. 2. Dispatch an appropriately sized shuttle and indicate the required stops on the map.
→ Classical routing algorithm is a better fit compared to ML-approach. This product doesn't need any ML models to work.- ❌ D. 1. Build a reinforcement learning model with tree-based classification models that predict the presence of passengers at shuttle stops as agents and a reward function around a distance-based metric. 2. Dispatch an appropriately sized shuttle and provide the map with the required stops based on the simulated outcome.
Rules for ML
- Google's best practices for Machine Learning Rule #1 Don't be afraid to launch a product without machine learning : Not All problem require ML solutions
Q3.
You were asked to investigate failures of a production line component based on sensor readings. After receiving the dataset, you discover that less than 1% of the readings are positive examples representing failure incidents. You have tried to train several classification models, but none of them converge. How should you resolve the class imbalance problem?
Imbalanced data & Non-convergence training
- A. Use the
class distribution to generate 10% positive examples.- B. Use a
convolutional neural network with max pooling and softmax activation.- ⭕ C. Downsample the data with upweighting to create a sample with 10% positive examples.
→ "Downsampling and upweighting technique" is the technique for the imbalanced data, making the model convergence faster.- D.
Remove negative examplesuntil the numbers of positive and negative examples are equal.
Downsampling & Upweighting
- Downsampling : Training on a disproportionately low subset of the majority class examples.
- Upweighting : adding an example weight to the downsampled class equal to the factor by which you downsampled.
Effect of Downsampling & upweighting
- ⭕ Faster convergence : During training, the model see the minority class more often, which will help the model converge faster. 훈련동안 소수 클래스에 이전보다 자주 학습하게 함으로써, 더 빠르게 수렴하는 데 도움이 된다.
- Saving on Disk space : By consolidating the majority class into fewer examples with larger weights ⇒ Savings allows more disk space for the minority class (so we can collect a greater number and a wider range of examples from that class).
- Model Calibration : Upweighting ensures our model is still calibrated ⇒ the outputs can still be interpreted as probabilities.
Q4.
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using
PySparkto conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data intoCloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
Scalable with Pyspark & SQL syntax available & Serverless tool for ML Pipeline using data from Cloud Storage to speed up development
- ❌ A. Use
Data FusionsGUI to build the transformation pipelines, and then write the data intoBigQuery.
- → SERVERLESS
- → BUT NOT SUPPORTS SQL SYNTAX
- ❌ B. Convert your
PySparkinto SparkSQL queries to transform the data, and then run your pipeline onDataprocto write the data intoBigQuery.
- → NOT SERVERLESS : Requires manual provisioning of clusters
- ❌ C. Ingest your data into
Cloud SQL, convert yourPySparkcommands into SQL queries to transform the data, and then use federated queries fromBigQueryfor machine learning.
- → NOT SERVERLESS : Requires manage instances
- → SUPPORTS SQL SYNTAX
- ⭕ D. Ingest your data into
BigQueryusing BigQuery Load, convert yourPySparkcommands intoBigQuerySQL queries to transform the data, and then write the transformations to a new table.
- → SERVERLESS
- → SUPPORTS SQL SYNTAX
Bigquery, Cloud SQL, Data Fusion
- Serverless services enables users to build, develop, deploy functions and applications as source code and removing the infrastructure management role.
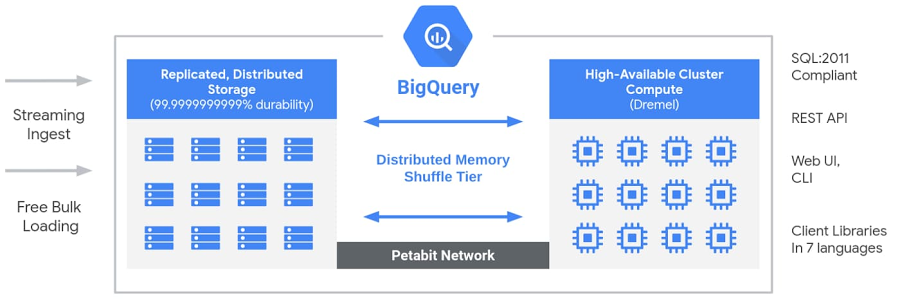
Bigquery
SERVERLESS (fully managed) no-ops, OLAP, enterprise data warehouse (EDW) with SQL and fast ad-hoc queries.
highly scalable data analysis service that enables businesses to analyze Big Data
Connected by google petabit network.
Recommended ELT option for SQL-minded teams
Batch Ingestion / Streaming Ingestion
Data Transfer Service (DTS) : automates data movement into BigQuery on a scheduled, managed basis
BigQuery Machine Learning (BQML) : support for limited models and SQL interface
2 key parts of BigQuery
- The Storage Service : works with bulk data and stream data ingest
- The Query Service : can also run queries on data in other locations. (e.g. csv files in cloud storage)
Cloud SQL
- cloud-based alternative to local MySQL, PostgreSQL, and Microsoft SQL Server databases.
- SUPPORTS SQL SYNTAX
- Managed solution that helps handles backups, replication, high availability and failover, data encryption, monitoring, and logging.
- Ideal for lift and shift migration from existing on-premises relational databases.
- NOT SERVERLESS : Requires manage instances
Cloud Data Fusion
Cloud Data Fusion |
|---|
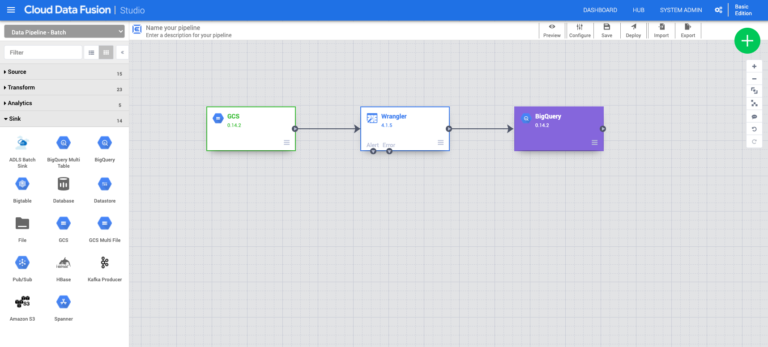 |
| Google’s cloud native, fully managed, scalable enterprise data integration platform. |
NOT SERVERLESS : But still requires low-level operations like when you’re configuring a Dataproc cluster. |
| Code-free self-service : Remove bottlenecks by enabling nontechnical users through a code-free graphical interface that delivers point-and-click data integration. |
| Integration metadata and lineage : Search integrated datasets by technical and business metadata. Track lineage for all integrated datasets at the dataset and field level. |
Enables bringing transactional, social or machine data in various formats from databases, applications, messaging systems, mainframes, files, SaaS and IoT devices, offers an easy to use visual interface, and provides deployment capabilities to execute data pipelines on ephemeral or dedicated Dataproc clusters in Spark. |
| (1) Real-time data integration : Replicate transactional and operational databases (SQL Server, Oracle and MySQL) directly into BigQuery with just a few clicks using Data Fusion’s replication feature. & Integration with Datastream allows you to deliver change streams into BigQuery for continuous analytics. & Use feasibility assessment for faster development iterations and performance/health monitoring for observability. |
| (2) Batch integration : Design, run and operate high-volumes of data pipelines periodically with support for popular data sources including file systems and object stores, relational and NoSQL databases, SaaS systems, and mainframes. |
| Powered by open source Cask Data Analytics Platform (CDAP) ⇒ makes the pipelines portable across Google Cloud or Hybrid or multi cloud environments. |
| Seamless operations : REST APIs, time-based schedules, pipeline state-based triggers, logs, metrics, and monitoring dashboards make it easy to operate in mission-critical environments. |
 |
'Certificate - DS > Machine learning engineer' 카테고리의 다른 글
| [EXAMTOPIC] Data Prep - Imbalanced data (0) | 2021.12.09 |
|---|---|
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q5-Q8 (0) | 2021.12.09 |
| [EXAMTOPIC] AI Platform built-in algorithms (0) | 2021.12.08 |
| [EXAMTOPIC] Dataflow pipelines for batch/online prediction (0) | 2021.12.08 |
| Which GCP services to use - No SQL Options for storage (Memorystore, Datastore, Bigtable) (0) | 2021.12.08 |