Q 49.
You work for an online travel agency that also sells advertising placements on its website to other companies. You have been asked to predict the most relevant web banner that a user should see next. Security is important to your company. The model latency requirements are 300ms, the inventory is thousands of web banners, and your exploratory analysis has shown that navigation context is a good predictor. You want to Implement the simplest solution. How should you configure the prediction pipeline?
- ❌ A. Embed the client on the website, and then deploy the model on AI Platform Prediction.
- ❌ B. Embed the client on the website, deploy the gateway on App Engine, and then deploy the model on AI Platform Prediction.
- ⭕ C. Embed the client on the website, deploy the gateway on App Engine, deploy the database on
Cloud Bigtablefor writing and for reading the users navigation context, and then deploy the model onAI PlatformPrediction.
→ Bigtable at low latency- ❌ D. Embed the client on the website, deploy the gateway on App Engine, deploy the database on Memorystore for writing and for reading the users navigation context, and then deploy the model on Google Kubernetes Engine.
Big Table
Bigtable
- Simple and integrated
- Fully managed service
- integration with Hadoop, Dataflow, and Dataproc
- Support for the open source HBase API standard
- High throughput at low latency
- ideal for storing very large amounts of data in a key-value store
- high read and write throughput at low latency for fast access to large amounts of data. Throughput scales linearly—you can increase QPS (queries per second) by adding Bigtable nodes. Bigtable is built with proven infrastructure that powers Google products used by billions such as Search and Maps.
Fast and performance
UseCloud Bigtableas the storage engine that grows with you from your first gigabyte to petabyte-scale for low-latency applications as well as high-throughput data processing and analytics.Seamless scaling and replication
Start with a single node per cluster, and seamlessly scale to hundreds of nodes dynamically supporting peak demand. Replication also adds high availability and workload isolation for live serving apps.Cluster resizing without downtime
Scale seamlessly from thousands to millions of reads/writes per second. Bigtable throughput can be dynamically adjusted by adding or removing cluster nodes without restarting, meaning you can increase the size of a Bigtable cluster for a few hours to handle a large load, then reduce the cluster's size again—all without any downtime.Flexible, automated replication to optimize any workload
Write data once and automatically replicate where needed with eventual consistency—giving you control for high availability and isolation of read and write workloads. No manual steps needed to ensure consistency, repair data, or synchronize writes and deletes. Benefit from a high availability SLA of 99.999% for instances with multi-cluster routing across 3 or more regions (99.9% for single-cluster instances).
Security
Data Pipeline - Security, Privacy, compliance, legal issues
- Cloud IAM : Resource access control
- API Gateway : Fully managed API Gateway
- Cloud Endpoints : API management system
Cloud IAM : Identity and Access Management
- grant granular access to specific Google Cloud resources
- helps prevent access to other resources
- the security principle of least privilege, which states that nobody should have more permissions than they actually need.
- With IAM, every API method across all Google Cloud services is checked to ensure that the account making the API request has the appropriate permission to use the resource.
API Gateway uses Identity and Access Management (IAM) to control access to your API*.
- view and grant roles using the permissions panel on the API Gateway > APIs or Gateways detail pages in the Google Cloud Console. Roles can also be granted using the API, or with the gcloud command-line tool.
- grant IAM Role title
Service Consumer, API Gateway Viewer, API Gateway Adminthe project level and at the service consumer level.
Endpoints is an API management system that helps you secure, monitor, analyze, and set quotas on your APIs using the same infrastructure Google uses for its own APIs*.
- After you deploy your API to Endpoints, you can use the Cloud Endpoints Portal to create a developer portal, a website that users of your API can access to view documentation and interact with your API.
Q 50.
Your team is building a convolutional neural network (CNN)_-based architecture from scratch. The _preliminary experiments running on your on-premises CPU-only infrastructure were encouraging, but have slow convergence. You have been asked to speed up model training to reduce time-to-market. You want to experiment with virtual machines (VMs) on Google Cloud to leverage more powerful hardware. Your code does not include any manual device placement and has not been wrapped in Estimator model-level abstraction. Which environment should you train your model on?
Scale tier
- ❌ A. A VM on Compute Engine and
1 TPUwith all dependencies installed manually.- ❌ B. A VM on Compute Engine and
8 GPUswith all dependencies installed manually.- ⭕ C. A Deep Learning VM with an
n1-standard-2 machine and 1 GPUwith all libraries pre-installed.- ❌ D. A Deep Learning VM with more powerful
CPU e2-highcpu-16 machineswith all libraries pre-installed.
Q 51.
You work on a growing team of more than 50 data scientists who all use AI Platform. You are designing a strategy to organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
Managing organization/Resources on AI Platform
- ❌ A. Set up restrictive IAM permissions on the AI Platform notebooks so that only a single user or group can access a given instance.
- ❌ B.
Separate each data scientistswork into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.- ⭕ C. Use labels to organize resources into descriptive categories. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources.
- ❌ D. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about AI Platform resource usage. In BigQuery, create a SQL view that maps users to the resources they are using
Labelsfor Monitoring groupings of related resources for Operational tasks- Add labels to AI Platform Prediction jobs, models, and model versions, then use those labels to organize resources into categories when viewing or monitoring the resources. For example, you can label jobs by team (such as engineering or research) and development phase (prod or test), then filter the jobs based on the team and phase.
- Labels available on operations, but these labels are derived from the resource to which the operation applies. You cannot add or update labels on an operation.
- A label : a key-value pair, where both the key and the value are custom strings.
list of all the things you can do with labels |
|---|
| - Identify resources used by individual teams or cost centers |
| - Distinguish deployment environments (prod,stage, qa, test) |
| - Identify owners, state labels. |
| - Use for cost allocation and billing breakdowns. |
| - Monitor resource groups via Stackdriver, which can use labels accessible in the resource metadata |
| Management tool Decision Tree |
|---|
Labelling and grouping your Google Cloud Platform resources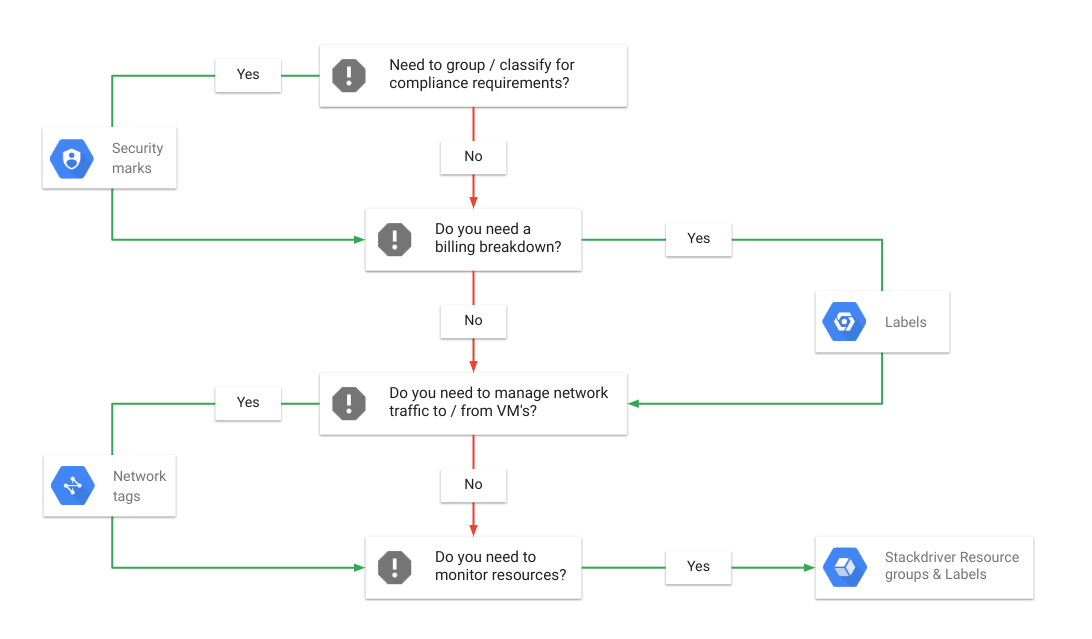 |
Monitoring performance and managing the cost of ML projects
- Investigate your system using application logs
- Use
Cloud Monitoringto track ML applications - Capture your spend data in a consistent format
- Attribute resource usage by using labels
- Understand and monitor your projects costs
- Control costs through budgets and alerting
- Take advantage of serverless
- Run your services in the same region
- Take advantage of discounts for compute resources
- Forecast costs to effectively plan and prioritize your cloud investment
| Resource Hierarchy |
|---|
 |
Q 52.
You are training a deep learning model for semantic image segmentation with reduced training time. While using a Deep Learning VM Image, you receive the following error: The resource 'projects/deeplearning-platforn/zones/europe-west4-c/acceleratorTypes/nvidia-tesla-k80' was not found. What should you do?
- ❌ A. Ensure that you have
GPU quota in the selected region. - ⭕ B. Ensure that the required GPU is available in the selected region.
- ❌ C. Ensure that you have preemptible GPU
quotain the selected region. - ❌ D. Ensure that the
selected GPU has enough GPU memory for the workload.
Issues while using Deep learning VM ; Quota, Notfound, Preemetible instances
EXAMTOPIC - Troubleshooting while using Deep Learning VM Image
- Quota exceeded : not enogh GPU/TPU quota, request for quota increase
- Resource not found : trying to use GPU in region where GPU is not available
- Preemptible instances: can't create preemptible instance from the UI, even though you have quota. use command line argument :
--preemptiblewhen setting up your new instance.
'Certificate - DS > Machine learning engineer' 카테고리의 다른 글
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q57-Q60 (0) | 2021.12.10 |
|---|---|
| [PMLE CERTIFICATE - EXAMTOPIC DUMPS Q53-Q56 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q45-Q48 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q41-Q44 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q37-Q40 (0) | 2021.12.10 |