Q 21.
You have deployed multiple versions of an image classification model on AI Platform. You want to monitor the performance of the model versions over time. How should you perform this comparison?
Continuous Evaluation on multiple version of ML model
- A. Compare the loss performance for each model on a held-out dataset.
- B. Compare the loss performance for each model on the validation data.
- C. Compare the receiver operating characteristic (ROC) curve for each model using the
What-If Tool.- ⭕ D. Compare the mean average precision across the models using the Continuous Evaluation feature.
→ In AI Platform Prediction, multiple model versions can be grouped together in a model resource. Each model version in one model should perform the same task, but they may each be trained differently. If you have multiple model versions in a single model and have created an evaluation job for each one, you can view a chart comparing the mean average precision of the model versions over time
What-If Tool (WIT)within notebook environments to inspect AI Platform Prediction models through an interactive dashboard.- What-If Tool integrates with
TensorBoard,Jupyter notebooks,Colab notebooks,JupyterHub. - Pre-installed on Notebooks TensorFlow instances.
- How to use the What-If Tool with a trained model that is already deployed on AI Platform.
- nice video regarding this
- What-If Tool integrates with
AI Platform Prediction - Continuous Evaluation : Compare mean average precision across models
- AI Platform Prediction - Continuous Evaluation : Compare mean average precision across models

- Continuous evaluation regularly samples prediction input and output from trained machine learning models that you have deployed to AI Platform Prediction. AI Platform
Data Labeling Servicethen assigns human reviewers to provide ground truth labels for your prediction input; alternatively, you can provide your own ground truth labels. Data Labeling Service compares your models' predictions with the ground truth labels to provide continual feedback on how your model is performing over time.
Q 22.
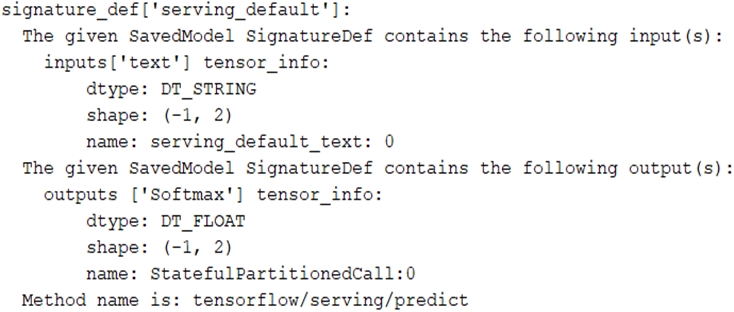
You trained a text classification model. You have the following SignatureDefs:
You started a TensorFlow-serving component server and tried to send an HTTP request to get a prediction using: headers = {"content-type": "application/json"} json_response = requests.post('http: //localhost:8501/v1/models/text_model:predict', data=data, headers=headers)
What is the correct way to write the predict request?
JSON type syntax
- A. data = json.dumps({“signature_name”: “seving_default”, “instances” : [[‘ab’, ‘bc’, ‘cd’]]})
- B. data = json.dumps({“signature_name”: “serving_default”, “instances” : [[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’]]})
- C. data = json.dumps({“signature_name”: “serving_default”, “instances” : [[‘a’, ‘b’, ‘c’], [‘d’, ‘e’, ‘f’]]})
- ⭕ D. data = json.dumps({“signature_name”: “serving_default”, “instances” : [[‘a’, ‘b’], [‘c’, ‘d’], [‘e’, ‘f’]]})
→shape (-1,2): represents a vector with any number of rows but only 2 columns.
Q 23.
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in
Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (PII) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?
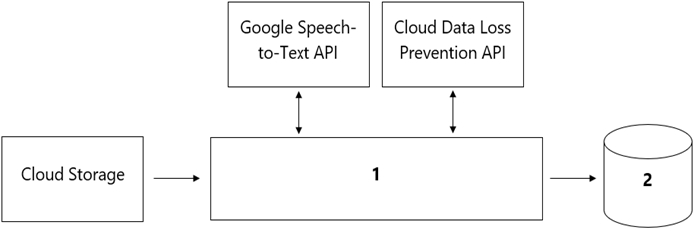
Contact Center AI
- ⭕ A. 1 = Dataflow, 2= BigQuery
- B. 1 = Pub/Sub, 2= Datastore
- C. 1 = Dataflow, 2 = Cloud SQL
- D. 1 = Cloud Function, 2= Cloud SQL
Contact Center AI
Cloud Dataflow- a managed, serverless service for unified stream & batch data processing requirements
- For strongly consistent, parallel data-processing pipelines
- Recommended to a strong engineering background
- Together with
Cloud Pub/Sub,Cloud Data Loss Prevention(DLP,Cloud Storage,BigQuery, and GCP’s other managed services, these solutions provide a great way to implement analytics pipelines that require minimal operations investment.
BigQuery- SQL 2011 compliant
- SQL 2011 compliant
24.
You are an ML engineer at a global shoe store. You manage the ML models for the company's website. You are asked to build a model that will recommend new products to the user based on their purchase behavior and similarity with other users. What should you do?
Recommendation system
- A. Build a
classification model- B. Build a
knowledge-basedfiltering model- ⭕ C. Build a collaborative-based filtering model
- D. Build a
regression model using the features as predictors
Recommendation system - 2 common candidate generation approaches
- Content-based filtering : similarity between items to recommend items similar to what the user likes.
- e.g. If user A watches two cute cat videos, then the system can recommend cute animal videos to that user.
- Collaborative filtering : similarities between queries and items simultaneously to provide recommendations.
- 추천엔진 - 데이터 필터링
- e.g. If user A is similar to user B, and user B likes video 1, then the system can recommend video 1 to user A (even if user A hasn’t seen any videos similar to video 1).
'Certificate - DS > Machine learning engineer' 카테고리의 다른 글
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q25-Q28 (0) | 2021.12.10 |
|---|---|
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q29-Q32 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q17-Q20 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q13-Q16 (0) | 2021.12.10 |
| [PMLE CERTIFICATE - EXAMTOPIC] DUMPS Q9-Q12 (0) | 2021.12.09 |