시계열 예측 데이터 분석 프로젝트를 진행하면서 활용해본 Shapley Values를 구현하고 해석합니다.
No more black box, explainable AI 머신러닝 모델의 Interpretability가 중요한 토픽이 되었고, 각각의 feature가 모델 예측에 어떻게 기여하는지 Feature importance를 파악하여 Feature Selection / Engineering 반영할 수 있는 방법은 다양하게 존재한다.
그 중 Shapley Values를 적용해 독립변수와 종속변수 사이의 관계를 해석해보고자 한다.
Shapley Values
Shapley Values 구현
Objective : SHAP을 활용하여 특성 기여도를 파악하고, 피쳐 엔지니어링에 반영 (pycaret과 함께 활용했다.)
from pycaret.regression import *
import shap
# initialize setup
ln_reg = setup(ln_df,
target='ln',
categorical_features=['day','month'],
train_size = 0.2,
normalize = True)
# Compare models (scoring mae)
comp = compare_models(sort = 'mae')
# Shapley Value
interpret_model(create_model('lightgbm'))
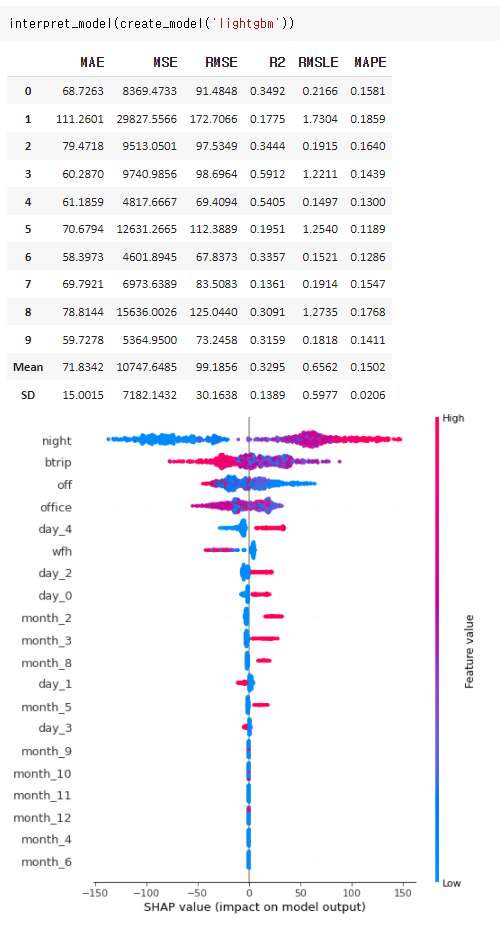
결과 해석
- night이 클수록 Shapley Value가 높고, 작을수록 Shapley Value가 낮다 :: 종속변수(ln)에 큰 기여
- btrip이 작을수록 Shapley Value가 높고, 클수록 Shapley Value가 낮다
- 월요일(day_0)일수록 종속변수(ln)에 큰 기여
'Data Science > Machine learning' 카테고리의 다른 글
| Transform Numeric Data - Normalization 입력 데이터 정규화 (0) | 2021.11.21 |
|---|---|
| k-means Clustering 클러스터링 (0) | 2021.11.21 |
| [Feature Selection] Permutation Importance (0) | 2021.08.02 |
| [Model Development] 파라미터 튜닝 - 모형 최적화 (GridSearchCV) (0) | 2021.07.15 |
| [Preprocessing] 범주형 변수 인코딩 (0) | 2021.07.11 |