Google Professional Data Engineer Certificate EXAMTOPIC DUMPS Q21-Q25
Q 22.
Your company has hired a new data scientist who wants to perform complicated analyses across very large datasets stored in
Google Cloud Storageand in a Cassandra cluster onGoogle Compute Engine. The scientist primarily wants to create labelled data sets for machine learning projects, along with some visualization tasks. She reports that her laptop is not powerful enough to perform her tasks and it is slowing her down. You want to help her perform her tasks. What should you do?
- ❌ A. Run a
local versionof Jupiter on the laptop.- ❌ B. Grant the user access to
Google Cloud Shell.- ❌ C. Host a visualization tool on a VM on
Google Compute Engine.- ⭕ D. Deploy
Google Cloud Datalabto a virtual machine (VM) on Google Compute Engine.
Use Cloud Datalab to easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively.
- Cloud Datalab ⇒ AI Notebooks ⇒
Vertex AI Workbench - Instantiate a Jupyter notebook on AI Platform.
- Datalab runs as a container inside a VM
Q 23.
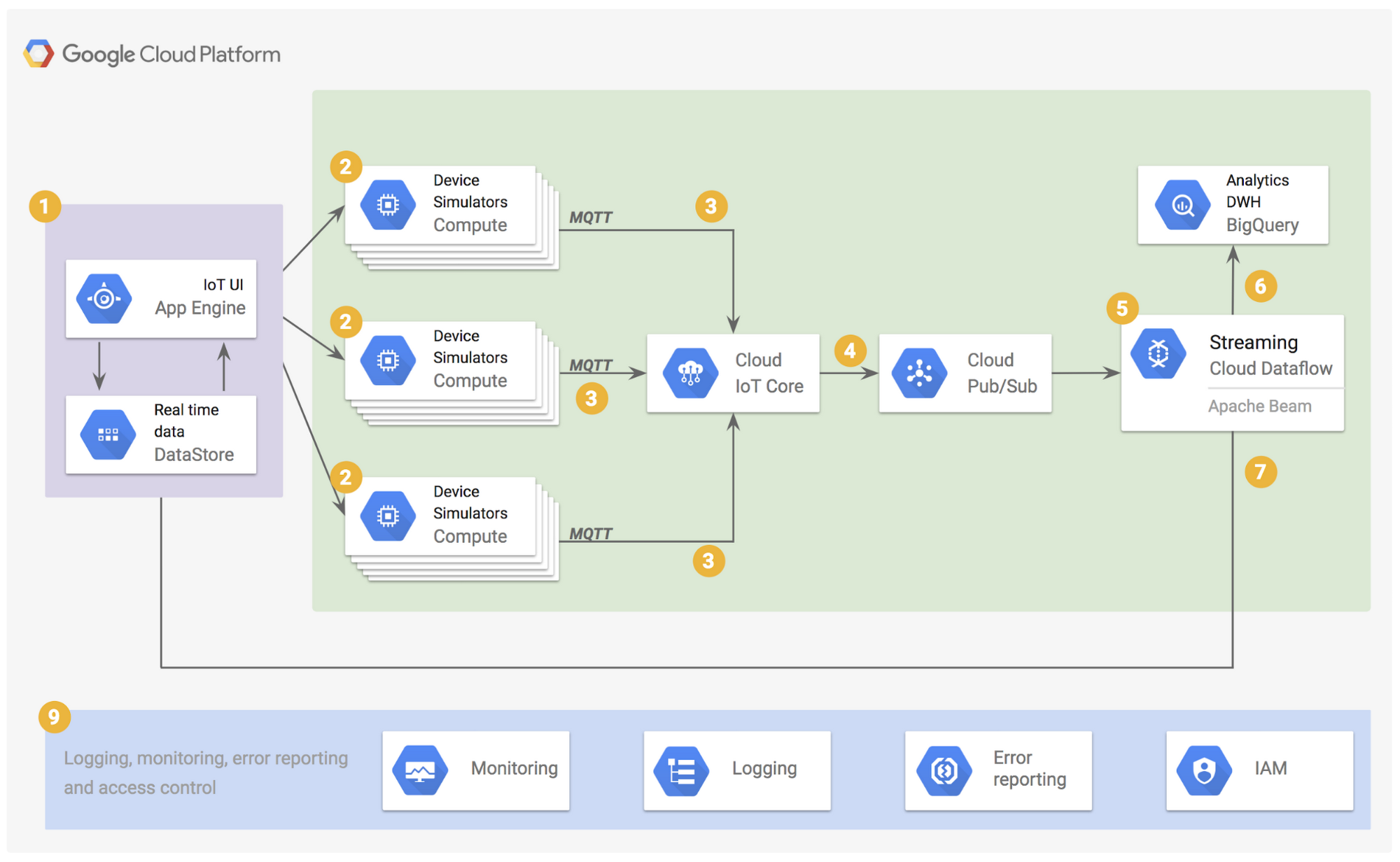
You are deploying 10,000 new Internet of Things devices to collect temperature data in your warehouses globally. You need to process, store and analyze these very large datasets in real time. What should you do?
- ❌ A. Send the data to Google Cloud
Datastoreand then export to BigQuery.- ⭕ B. Send the data to Google Cloud
Pub/Sub, stream CloudPub/Subto Google CloudDataflow, and store the data in GoogleBigQuery.- ❌ C. Send the data to
Cloud Storageand then spin up an Apache Hadoop cluster as needed in GoogleCloud Dataprocwhenever analysis is required.- ❌ D. Export logs in batch to Google Cloud Storage and then spin up a Google
Cloud SQLinstance, import the data from Cloud Storage, and run an analysis as needed.
Pubsub for realtime, Dataflow for data pipeline, Bigquery for analytics
Q 25.
You want to use
Google Stackdriver Loggingto monitor Google BigQuery usage. You need an instant notification to be sent to your monitoring tool when new data is appended to a certain table using an insert job, but you do not want to receive notifications for other tables. What should you do?
- ❌ A. Make a call to the
Stackdriver APIto list all logs, and apply an advanced filter.
→ Not Notifiying anything- ❌ B. In the
Stackdriver loggingadmin interface, and enable a log sink export toBigQuery.
→ Not Notifiying anything- ❌ C. In the Stackdriver logging admin interface, enable a log sink export to
Google Cloud Pub/Sub, and subscribe to the topic from your monitoring tool.
→ Notifying but No filter on what will be notified- ⭕ D. Using the
Stackdriver API, create a project sink with advanced log filter to export toPub/Sub, and subscribe to the topic from your monitoring tool.
Google Stackdriver Logging for monitoring BigQuery usage & using pub/sub for notifications
Detecting and responding to Cloud Logging events in real-time
Automate your response to a Cloud Logging event | Google Cloud Blog
...
filter: resource.type="gce_firewall_rule" operation.last=true
# Properties for the pubsub destination to be created.
pubsubProperties:
topic: fw_log_pubsub_topic_dest
...Stackdriver
For store, search, analyze, monitor, and alert on log data and events.
Logging sink
Using a Logging sink, you can build an event-driven system to detect and respond to log events in real time. Cloud Logging can help you to build this event-driven architecture through its integration with Cloud Pub/Sub and a serverless computing service such as Cloud Functions or Cloud Run.
`
Pub/Sub topic
In Pub/Sub, you can create a topic to which to direct the log sink and use the Pub/Sub message to trigger a cloud function.
'Certificate - DS > Data engineer' 카테고리의 다른 글
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q31-Q35 (0) | 2022.01.25 |
|---|---|
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q26-Q30 (0) | 2022.01.25 |
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q6-Q10 (0) | 2022.01.24 |
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q1-Q5 (0) | 2022.01.24 |
| [DATA ENGINEER LEARNING PATH] Sample Questions (0) | 2022.01.18 |




