Souce&reference : BigQuery explained: Storage overview, and how to partition and cluster your data for optimal performance | Google Cloud Blog
SUMMARY
- Both
partitioningandclusteringcan improve performance and reduce query cost.Partitioningis recommended over tablesharding, becausepartitionedtables perform better.- Partitioning
- to know query costs before a query runs. Partition pruning is done before the query runs, so you can get the query cost after partitioning pruning through a dry run.
- Clustering
- don't need strict cost guarantees before running the query. Cluster pruning is done when the query runs, so the cost is known only after the query finishes.
- Sharding
- With sharded tables, BQ must maintain a copy of the schema and metadata for each table.
- adds to query overhead and affects query performance.
Partitioning, Clustering
Both partitioning and clustering can improve performance and reduce query cost.
| - | Applications |
|---|---|
| Partition | 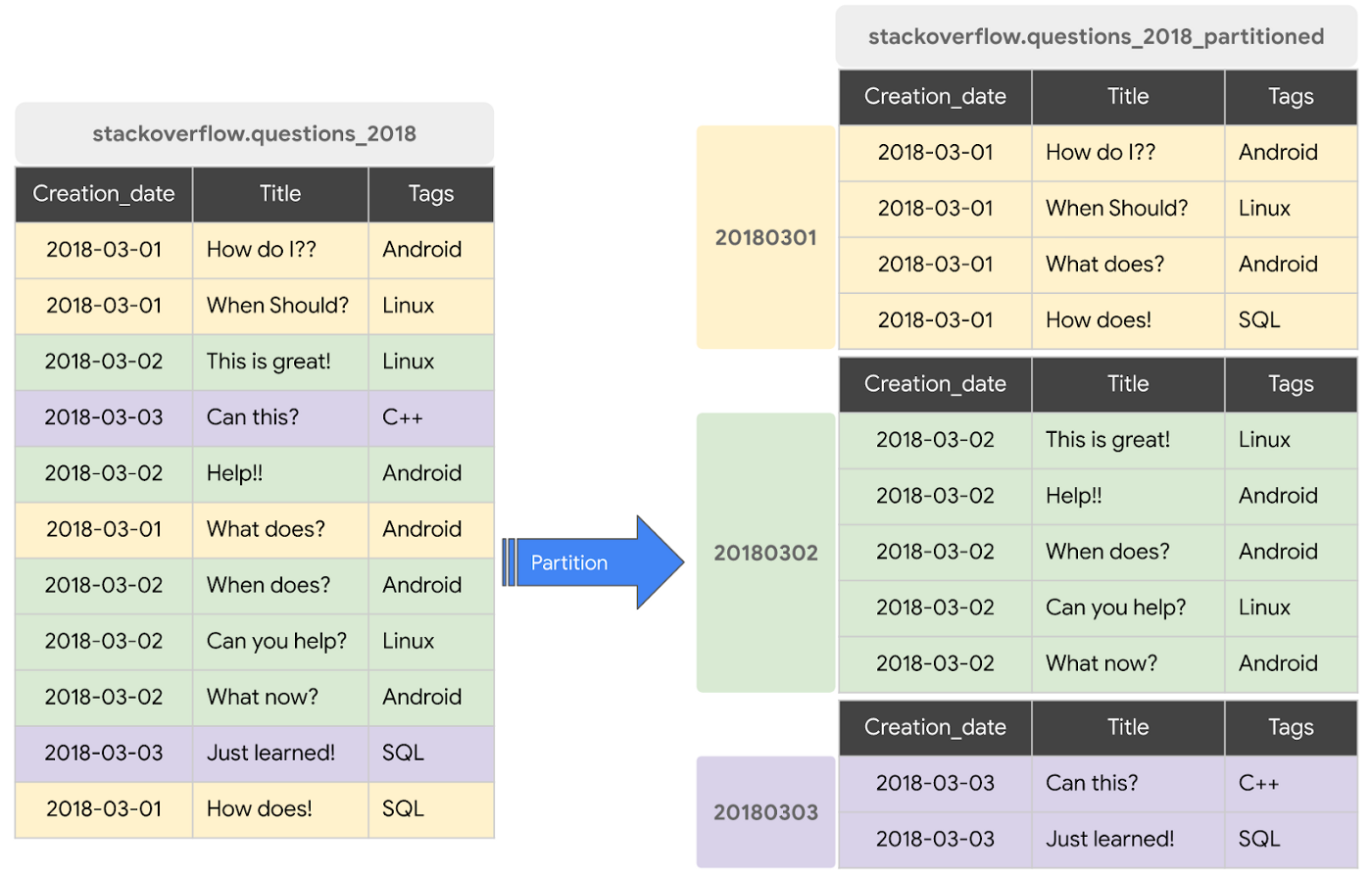 |
| Partition & Clustering | 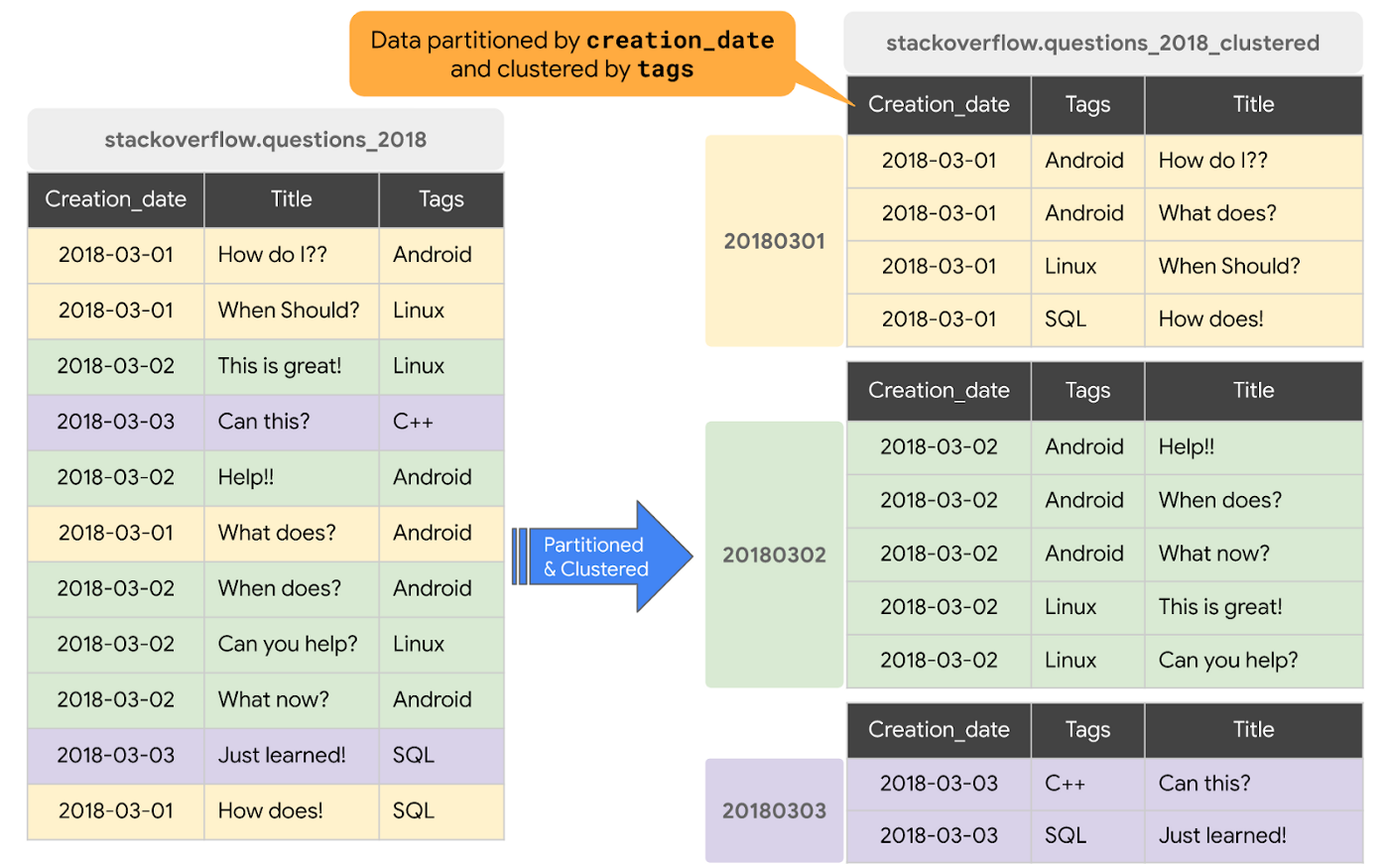 |
1. Partitioning
- You want to know query costs before a query runs.
- Partition pruning is done before the query runs, so you can get the query cost after partitioning pruning through a dry run.
- Cluster pruning is done when the query runs, so the cost is known only after the query finishes.
- You need partition-level management.
- For example, you want to set a partition expiration time, load data to a specific partition, or delete partitions.
- You want to specify how the data is partitioned and what data is in each partition.
- For example, you want to define time granularity or define the ranges used to partition the table for integer range partitioning.
Partitioned tables
A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data.
- By dividing a large table into smaller partitions, you can improve query performance, and you can control costs by reducing the number of bytes read by a query.
- Ways to partition BigQuery Tables :
2. Clustering
- You don't need strict cost guarantees before running the query.
- You need more granularity than partitioning alone allows. To get clustering benefits in addition to partitioning benefits, you can use the same column for both partitioning and clustering.
- Your queries commonly use filters or aggregation against multiple particular columns.
- The cardinality of the number of values in a column or group of columns is large.
Sharding
Table sharding is the practice of storing data in multiple tables, using a naming prefix such as [PREFIX]_YYYYMMDD.
- Partitioning is recommended over table sharding, because partitioned tables perform better.
- With sharded tables,
BigQuerymust maintain a copy of the schema and metadata for each table.BigQuerymight also need to verify permissions for each queried table. This practice also adds to query overhead and affects query performance.
'Certificate - DS > Data engineer' 카테고리의 다른 글
| Cloud Pub/Sub and Kafka (0) | 2022.02.21 |
|---|---|
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q121-Q125 (0) | 2022.02.17 |
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q111-Q115 (0) | 2022.02.17 |
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q96-Q100 (0) | 2022.02.17 |
| [PDE CERTIFICATE - EXAMTOPIC] DUMPS Q91-Q95 (0) | 2022.02.17 |